多模态向3D扩展!Meta用视觉模型首次看懂3D世界,媲美纯视觉专家模型
Meta和普林斯顿大学的研究团队用一种极其简单的方法,让一个标准的视觉语言模型(VLM)在3D深度估计任务上,首次达到了与那些经过特殊设计、专门训练的纯视觉专家模型相媲美的准确度。

视觉语言模型,在理解图像里的是什么(语义)方面已经非常强大,但它们始终搞不清有多远(3D信息),缺乏基本的空间感。
长期以来,学术界普遍认为,要让VLM具备精确的3D感知能力,必须对它进行外科手术:要么修改其底层架构,增加专门处理3D信息的模块;要么设计复杂的损失函数,像教一个孩子学物理公式一样,强行灌输空间几何知识。
而DepthLM这篇论文的惊人之处在于,它证明了这些复杂的改造全都不需要。
研究人员发现,VLM之所以在3D世界里表现得像个睁眼瞎,根本原因只有两个:它看不懂你在问图中哪个点,以及它被不同相机拍出的照片搞混了。
解决了这两个看似简单的问题后,只用标准的文本监督微调和极其稀疏的训练数据,就足以唤醒VLM潜藏的强大3D理解能力。
这个发现,为构建更通用、更强大的多模态AI系统,开辟了一条简洁高效的新路径。
视觉语言模型迷失在3D世界
视觉语言模型的发展,是AI领域近年来最激动人心的故事之一。通过将强大的语言模型与视觉模型连接,AI第一次能够像人一样,通过自然语言对话来完成各种视觉任务。
但在这片繁荣之下,3D理解能力始终是VLM的一块短板。

即便是GPT-5这样的顶级模型,在被问及图中物体的距离时,也常常给出离谱的答案。它们的表现甚至不如一些最基础的纯视觉模型。
与此同时,在度量深度估计这个专门的赛道上,纯视觉模型早已进化到了超越人类的精准度。像ZoeDepth和Metric3D系列模型,通过设计专门的预测头、利用相机内部参数等复杂技术,实现了零样本的精确测距。
一边是越来越全能但空间感模糊的VLM,另一边是越来越精准但功能单一的专家模型。这两条技术路线的巨大差异,引出了一个核心问题:VLM能否在保持其通用性的前提下,学会专家级的3D技能?
过去的研究尝试过多种方法,试图弥合这一差距。
一些工作,如SpatialVLM,尝试知识蒸馏,即将纯视觉专家模型的输出结果(比如深度图)翻译成文本,再用来训练VLM。但这就像二手知识,在传递过程中容易失真和累积误差。
另一些工作,如SpatialBot,则更直接,在VLM的架构中加入一个额外的模块,专门用来处理深度图。但这牺牲了VLM的简洁性和通用性,让它变成了一个缝合怪。
还有一些最新的研究也探索了让VLM进行像素级深度估计,但它们的方法并没有从根本上解决问题,所以准确度依然远低于专家模型。
DepthLM的研究团队决定另辟蹊径。他们没有上来就动手改造模型,而是先做了一系列诊断性实验,试图找出VLM在3D理解上失败的根本原因。
VLM的病根其实很简单
研究团队从提示设计、训练损失和数据处理三个方面,对VLM进行了细致的体检,并得出了四个关键发现。
第一个发现:VLM看不懂文字坐标,但看得懂图上的箭头。
要让VLM估计一个点的深度,首先得告诉它你要问的是哪个点。之前的方法通常是在文本提示里写上这个点的坐标,比如坐标(X, Y)离相机有多远?
实验证明,这种方式效率极低。VLM很难将抽象的文本坐标精确地映射到图像的具体像素位置上,尤其是在物体繁多、边界复杂的室内场景中,一个小小的定位误差就可能让它张冠李戴。
于是,研究人员尝试了一种更直观的方式:视觉提示。他们在输入图片上直接画一个箭头或者标记,指向要查询的像素,然后提问:这个点距离相机多少米?
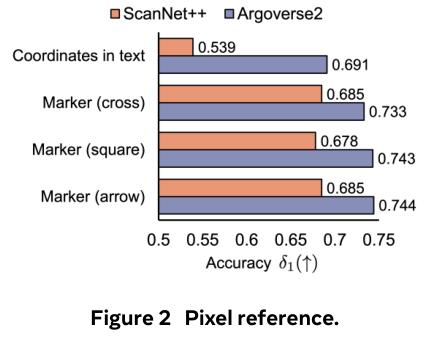
结果立竿见影。如图所示,改用视觉提示后,模型的准确度大幅提升。尤其是在室内数据集ScanNet++上,准确度指标直接高了0.15。这个发现说明,VLM对图像内的视觉标记的理解,远比对文本坐标的理解要好。
第二个发现:标准的监督微调(SFT)比复杂的强化学习更高效。
在训练方法上,研究人员比较了两种主流技术:监督微调(SFT)和强化学习(RL)。SFT就像是老师手把手教学生,直接告诉它正确答案。RL则更像是在探索中学习,模型做出回答后,根据答案的好坏给予奖励或惩罚。
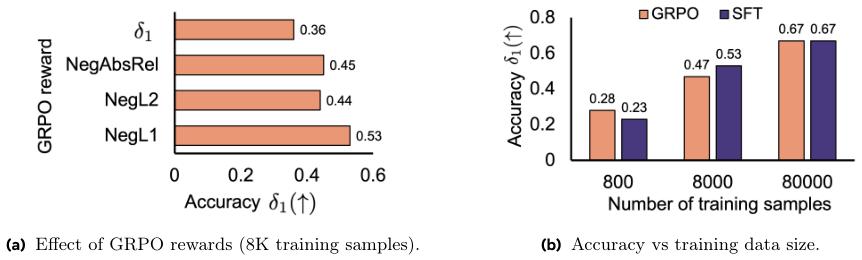
实验结果显示,在给予相同数量的训练样本时,两种方法最终能达到的准确度相差无几。
但RL的训练成本要高得多,每个样本的处理时间是SFT的8到16倍。对于需要大规模训练的3D理解任务来说,SFT显然是更经济、更高效的选择。
第三个发现:VLM会被不同相机的焦距搞糊涂,统一焦距是关键。
训练深度估计模型时,一个核心难题是相机模糊性。来自不同相机拍摄的照片,即便看起来相似,其内在的尺度也可能完全不同。直接把这些数据混在一起训练,模型能学会相对远近,但学不会绝对的米、厘米等度量单位。
研究人员测试了四种处理该问题的方法,包括直接混合训练、在文本提示中加入相机参数、让模型自己预测相机参数,以及在训练前通过图像增强来统一所有照片的焦距。
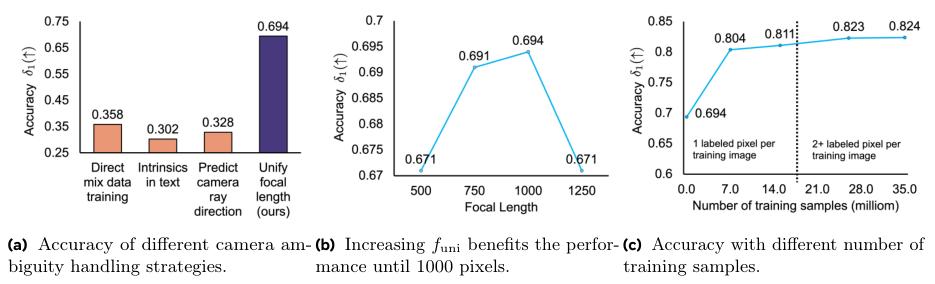
统一焦距的效果一骑绝尘,准确度比其他方法高出一倍以上。这个结果表明,在不改变架构的前提下,VLM自身很难从图像中推断出相机的差异。而通过一个简单的预处理步骤统一焦距,就能有效解决这个问题。
第四个发现:图像的多样性远比标注的密度更重要。
纯视觉专家模型通常需要在大规模的密集标注数据集上训练,一张训练图片里成千上万个像素点都有深度标注。而VLM的训练样本,每个样本只标注一个点的深度。
一个自然的问题是:VLM需要看多少个标注点,才能赶上专家模型?
答案出人意料。
当每个训练图像只提供1个标注像素时,模型的准确度指标(δ1)就已经超过了0.8,达到了与许多专家模型相当的水平。
这个惊人的结果揭示了一个深刻的道理:对于VLM学习3D理解而言,见识到更多不同场景的图像(多样性),比在同一张图像上看更多标注点(密度)要重要得多。VLM强大的泛化能力,让它能从极其稀疏的信号中,举一反三地学会通用的3D知识。
DepthLM的完整方法
基于以上四个核心发现,DepthLM的最终方法变得异常简洁。
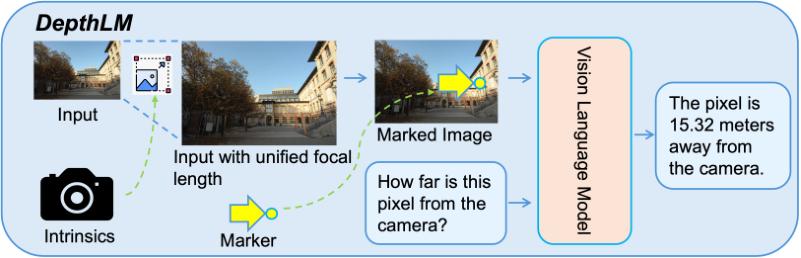
整个流程可以概括为三步。
第一步,像素参考。在输入图像上,直接用一个视觉标记(比如小箭头)指出要查询的像素点。
第二步,解决相机模糊性。在训练前,根据每张图片的相机内参,将其尺寸进行调整,使得所有图片的等效焦距都统一到一个预设值(例如1000像素)。
第三步,架构与训练。使用一个标准的、预训练好的VLM架构,不做任何修改。然后采用标准的监督微调(SFT)方法进行训练,损失函数就是最基础的交叉熵损失,不需要任何额外的回归或正则化项。
就是这样。没有复杂的架构改造,没有花哨的损失函数,只用了几个简单而关键的技巧,就让一个普通的VLM脱胎换骨。
更重要的是,这套框架具有极强的通用性。由于不依赖于任何任务特定的设计,它可以被无缝地扩展到其他更复杂的3D理解任务上。
研究人员展示了将同一个DepthLM模型用于另外五个任务的能力,包括估计物体的主轴距离、到达某点所需的速度和时间、两点之间的距离,以及估计相机在两张图片之间的移动距离。

这些任务涵盖了从单点查询到多点推理,再到多图像理解的复杂场景,充分证明了DepthLM框架的灵活性和强大潜力。
实验结果:VLM首次比肩专家模型
实验结果有力地证明了DepthLM的有效性。
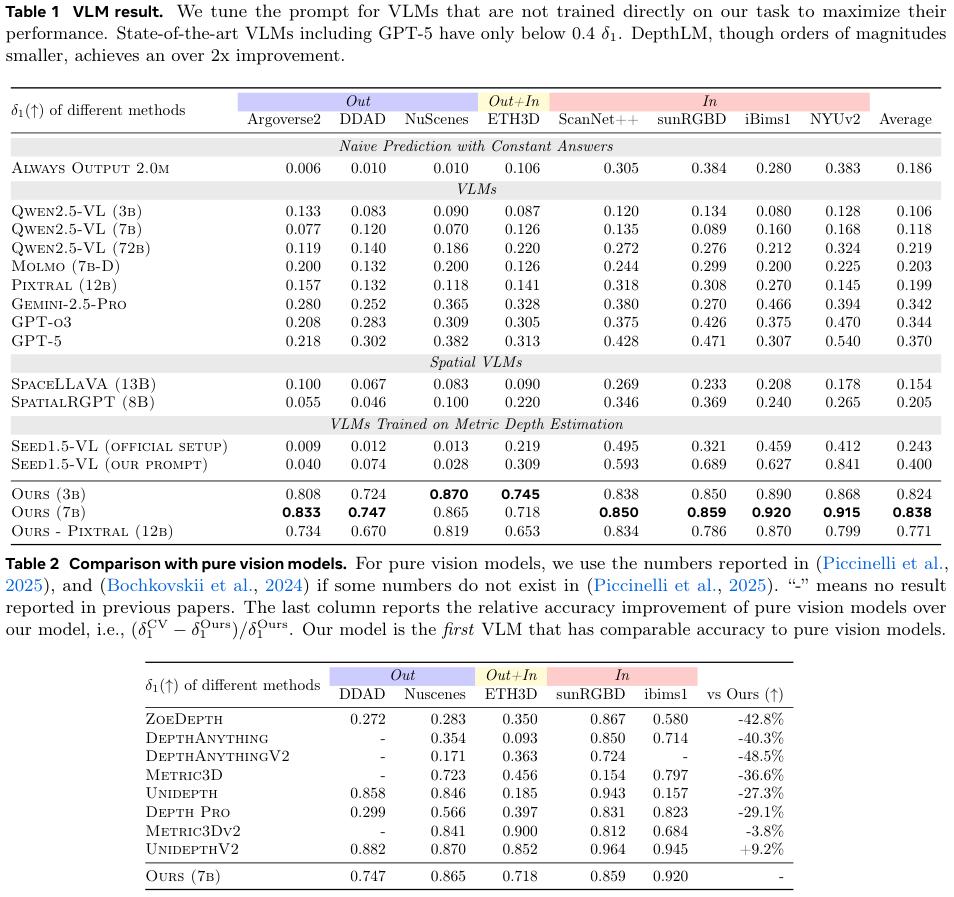
在与最顶尖的纯视觉专家模型的较量中(表2),DepthLM同样不落下风。它的性能超过了Metric3Dv2等一众强手,与最先进的UnidepthV2也基本处于同一水平线。这是VLM首次在度量深度估计这项核心3D任务上,达到了与专家模型并驾齐驱的水平。
有趣的是,尽管DepthLM只在稀疏的单点上进行训练,但它已经具备了生成高质量3D点云的能力。研究人员通过逐点查询的方式,生成了完整的场景点云。

DepthLM生成的点云不仅尺度准确,而且在物体边界的处理上,表现出一种独特的优势。纯视觉模型为了追求表面的平滑,往往会过度平滑掉物体的边缘,导致细小的物体(如路灯杆)与背景融为一体。而DepthLM自然地保留了清晰的物体边界,几乎没有产生飞行点(即悬浮在空中的噪点),这对于需要精确避障的机器人等应用至关重要。
在多任务学习方面,DepthLM的优势更加明显。
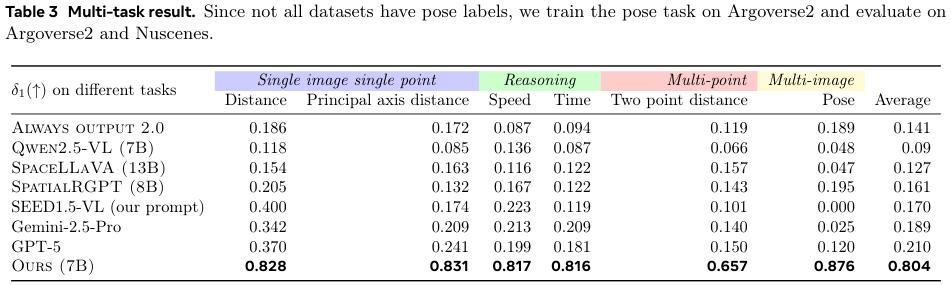
一个统一训练的DepthLM模型,在六个不同的3D任务上都取得了超过0.8的平均准确度。相比之下,包括GPT-5在内的其他VLM在这些更复杂的任务上几乎完全失效。例如,当被问及相机移动了多远时,GPT-5可能会在一个实际移动了5米的场景中回答0米。这种灾难性的失败,根源在于它们连基本的度量尺度都无法理解。
DepthLM的成功,不仅在于它提升了VLM的3D理解能力,更在于它指明了一条通往更通用、更强大AI的道路:不需要无休止地增加模型的复杂性,而是要回到第一性原理,找到问题的根本症结,并用最简洁的方法去解决它。
这项研究为机器人、自动驾驶、增强现实等所有需要精确空间感知的领域,提供了一个极具潜力的新范式。
未来,我们或许不再需要为每个3D任务都训练一个专门的模型,一个像DepthLM这样经过简单点拨的通用VLM,就足以看懂并驾驭我们这个三维的物理世界。
参考资料:
https://arxiv.org/abs/2509.25413
https://github.com/facebookresearch/DepthLM_Official
https://huggingface.co/facebook/DepthLM
END
暂无评论,快来抢沙发吧!