NeurIPS 2025|当AI理解几何:ETHz提出GAOT,让神经算子在任意形状上实现高效可扩展的PDE求解
 图片
图片作者 | 论文团队
编辑 | ScienceAI
想象一下,如果 AI 能真正理解复杂几何的形状,并快速预测其中的物理场分布 —— 无论是汽车外壳的气流走向,还是飞机机翼上的压力变化,都能在几秒内被准确模拟,而不再依赖昂贵的数值仿真。
这正是 Geometry Aware Operator Transformer(GAOT)所尝试实现的目标。该研究由 ETH Zurich 与 CMU 合作完成,并被 NeurIPS 2025 正式接收。
GAOT 提出了一种面向任意几何域的高效神经算子框架,不仅显著提升了 PDE 学习的精度与鲁棒性,更在计算可扩展性(scalability)上取得了实质性突破。
 图片
图片论文标题:Geometry Aware Operator Transformer as an Efficient and Accurate Neural Surrogate for PDEs on Arbitrary Domains
论文连接:https://arxiv.org/abs/2505.18781
项目主页:https://camlab-ethz.github.io/GAOT
1. 背景 | 当 PDE 遇上复杂几何
偏微分方程(PDE)是描述自然规律的基本语言,从流体力学到材料模拟,它支撑着几乎所有连续物理系统的建模与设计。传统数值方法(如有限元、有限差分)虽然精确,但在复杂几何或高分辨率网格上计算代价极高。神经算子(Neural Operator)希望通过数据驱动的方式学习 PDE 的解算映射,从而实现近乎实时的预测。
然而,现有神经算子仍面临两大瓶颈:
多数模型只能在规则网格上工作,难以推广至任意几何;
在大规模输入下,计算效率和显存占用成为关键限制。
2. 方法 | Geometry-Aware Operator Transformer (GAOT)
GAOT 的目标是让神经算子同时具备几何感知能力与计算效率。
它在经典的 编码–处理–解码(encode–process–decode) 框架上引入了两项核心创新:
1. 🕸 多尺度注意力图神经算子(MAGNO)
在编码与解码阶段,通过多尺度邻域聚合与注意力机制整合不同尺度的几何特征,实现跨尺度的物理建模。
2. 📐 几何嵌入(Geometry Embedding)
为每个点提取局部统计特征(邻域密度、平均距离、主方向等),将几何信息显式注入模型,提高对复杂几何域的敏感性。
同时,GAOT 在潜空间中采用了 Vision Transformer 式的 patch 机制,兼顾全局建模能力与计算效率。
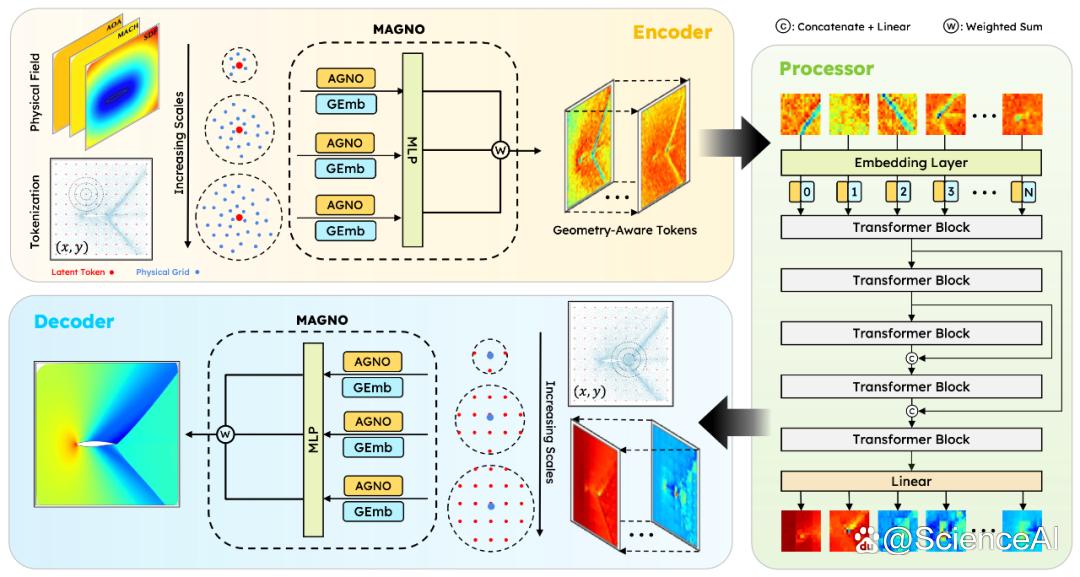 图片
图片图 1: GAOT 框架结构示意。结合几何嵌入与多尺度注意力,实现任意几何域上的 PDE 求解。
3. 工程洞察 | 从计算瓶颈出发的可扩展性优化
GAOT 的另一核心亮点,是基于对计算与显存瓶颈的系统分析所提出的一系列架构优化。
团队发现:
显存瓶颈主要来自 Encoder 与 Decoder,它们在稀疏图上的邻域聚合需要大量边级计算;
计算瓶颈主要集中在 Processor(Transformer 部分),其注意力计算随 token 数量平方增长,是决定训练吞吐率的关键环节。
为此,GAOT 设计了针对性优化策略:
1. 图缓存与异步加载
预存点云邻接结构,避免重复构图,并支持异步的图构建与模型计算。
2.Encoder/Decoder 顺序处理 + Processor 批处理
对编码器和解码器采用顺序化处理,能有效缓解大 batch size 下的显存峰值;同时对 Processor 采用计算密集型操作, 进行批量并行计算,在显存受限时仍保持高吞吐率。
3. 可选边采样(Edge Mask)策略
在极大规模数据上采用边采样策略,在几乎不损失精度的情况下显著节省内存,并提升模型泛化能力。
这些优化使 GAOT 在输入可扩展性(input scalability) 和模型可扩展性(model scalability)上都较主流算子模型表现更优。
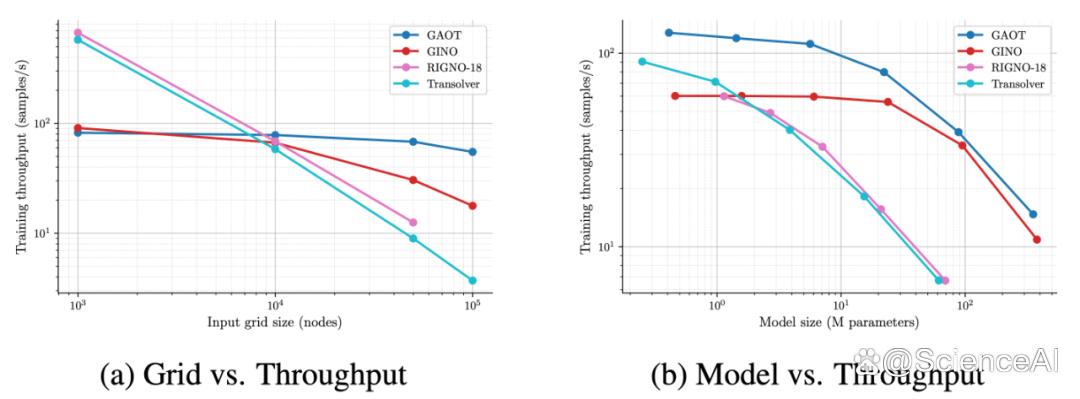 图片
图片图 2:训练吞吐率与模型规模可扩展性。随输入网格与模型规模增大时,GAOT 仍保持最高训练吞吐率,展现出优异的输入与模型可扩展性。
同时,它成为首个在 9 百万节点(9M-point) 的 DrivAerML 数据集上实现全分辨率(full-resolution)训练的神经算子模型 —— 这一规模此前被认为难以在单卡 GPU 上完成。
 图片
图片图 3: 流场预测结果对比(DrivAerML 与 NASA-CRM)
4. 实验 | 同时实现精度、效率与可扩展性
GAOT 在 28 个 PDE 基准任务上,与共计 14 个代表性基线模型进行了全面评测,覆盖时间相关与时间无关问题、规则网格与随机点云、二维到三维工业级仿真等多种场景。结果显示:
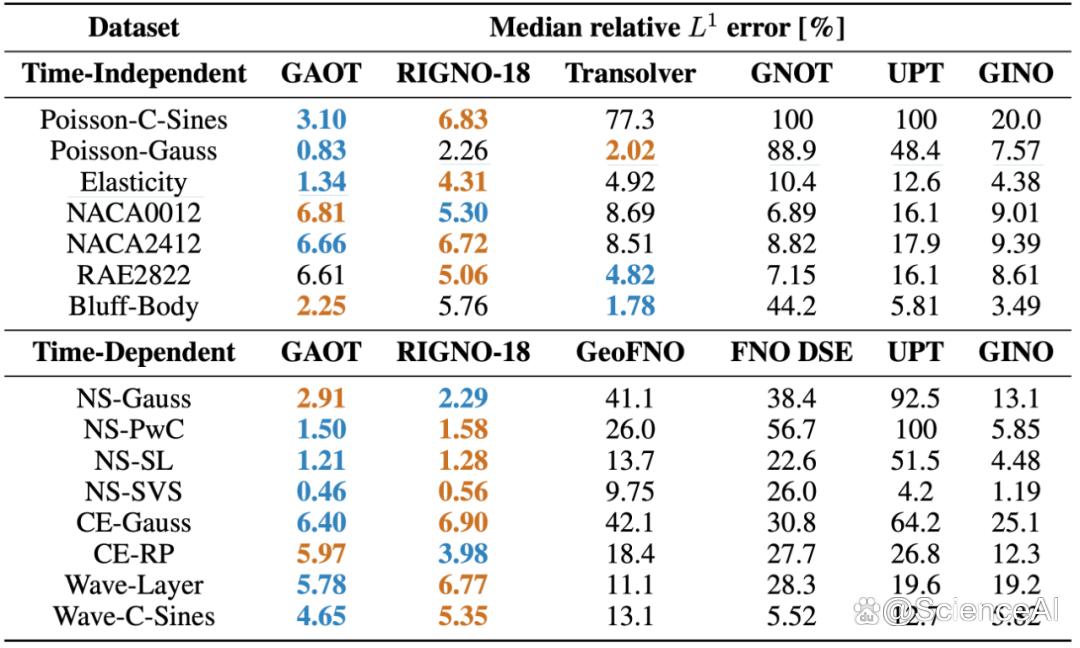 图片
图片表 1: 时间相关与时间无关任务基准结果
在几乎所有任务中取得最佳或次优性能;
训练吞吐量较代表性模型(GINO、RIGNO、Transolver)提升约 50%;
推理延迟降低 15–30%;
在三维工业 CFD 数据集(DrivAerNet++、DrivAerML、NASA-CRM)上均取得最新最优结果(SOTA);
在 DrivAerNet++ 数据集上,壁面压力和剪应力预测精度较次优模型分别提升约 15% 和 30%。
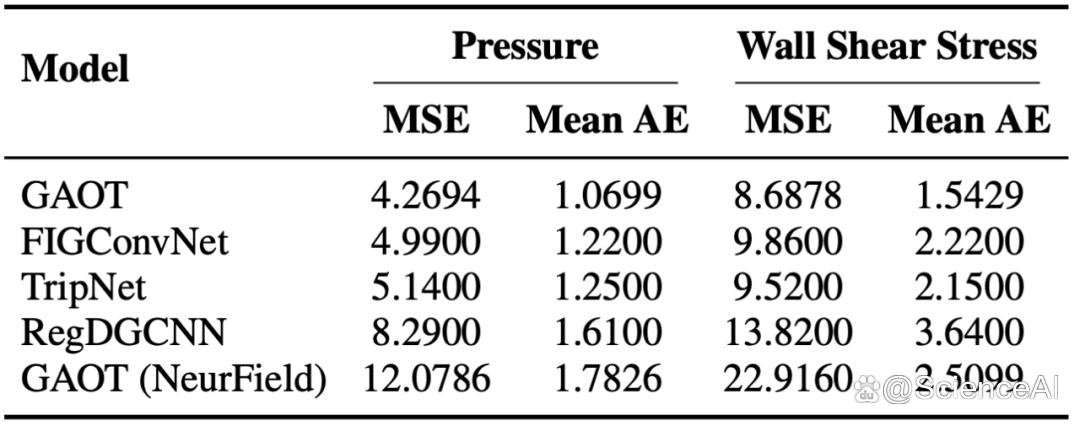 图片
图片表 2: DrivAerNet++ 数据集误差分析
值得注意的是,GAOT 在一个综合评测中 —— 涵盖八个关键维度:
精度(Accuracy)、鲁棒性(Robustness)、训练吞吐率(Throughput)、推理延迟(Latency)、输入可扩展性(Input Scalability)、模型可扩展性(Model Scalability)、以及在时间相关 / 无关任务上的稳定性(Time-Dependent / Time-Independent Performance)—— 均达到了最优或并列最优表现。
换言之,GAOT 在三类主流模型范式中 ——
Transformer-based(如 Transolver、GNOT)
Graph-based(如 RIGNO)
FNO-based(如 GINO、GeoFNO)
都展现出显著的综合优势,首次在同一框架下兼顾了精度、效率与可扩展性。
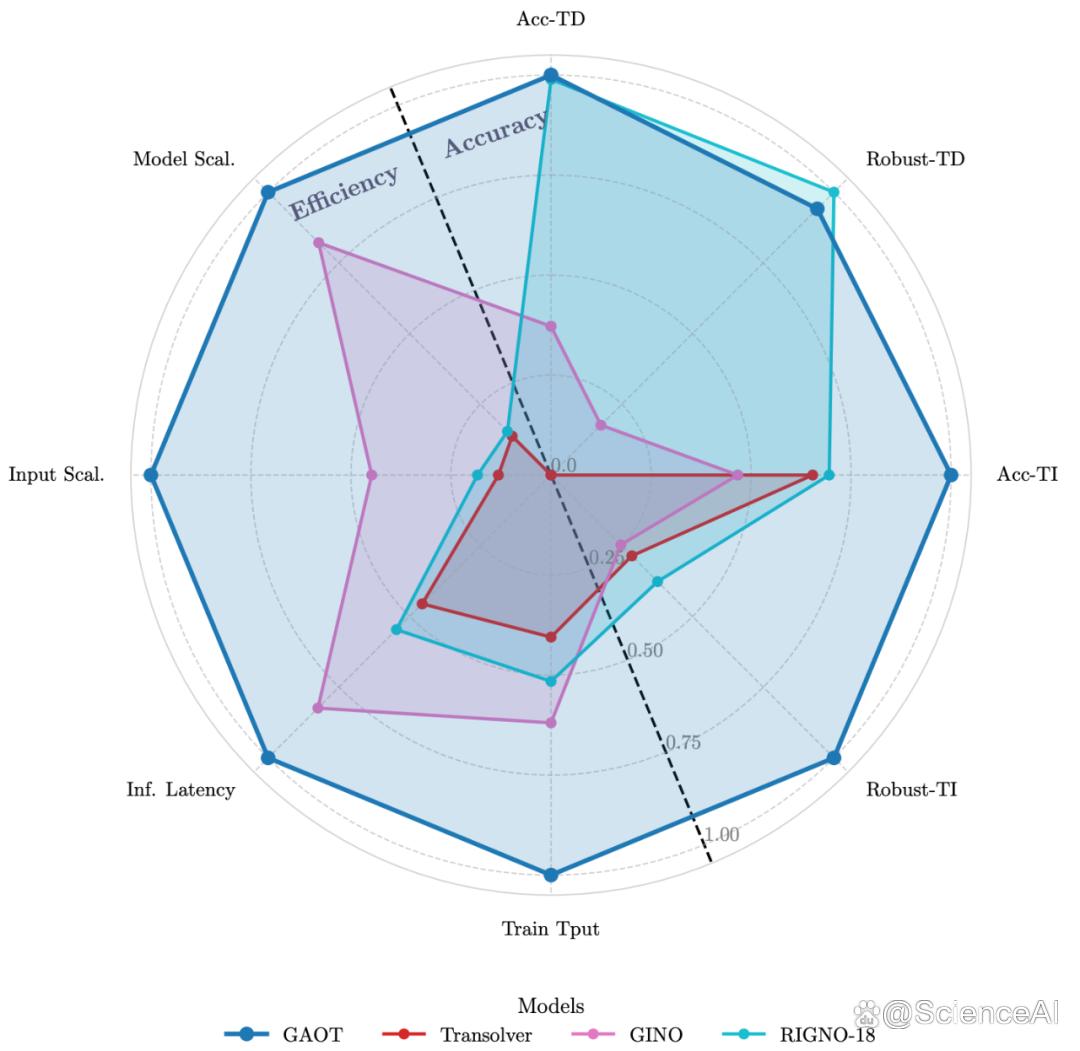 图片
图片图 4: 八维度综合性能评估
5. 总结 | 面向大规模科学计算的高效神经算子
GAOT 不仅是一个新的神经算子架构,更是一种对「效率与可扩展性」的系统性重思。它通过对计算结构的深入理解,实现了从算法设计到工程实现的协同优化。这一成果表明,AI 不仅可以「近似」数值求解器,还能在理解几何与物理规律的基础上,以高效、可扩展的方式重现科学计算的核心过程。未来,团队计划将 GAOT 扩展到上亿网格的全精度训练,并作为 backbone 开发多模态微分方程大模型,探索其在更广泛科学问题中的应用潜力。
暂无评论,快来抢沙发吧!